

A curated on-ground experience for global teams building AI product innovation across Sub-Saharan Africa (SSA)
By the YUX Design Team
In March 2026, our team facilitated a comprehensive research immersion for a Big Tech company in Nairobi, Kenya.
What is product immersion? Product Immersion is a structured, multi-day experience that places product teams inside the markets they are building for.
These immersions are critical because they move global product and marketing leaders away from relying solely on aggregated data or assumptions, directly connecting them with the African market. When it comes to building AI products, firsthand experience and primary research remain some of the most powerful tools for understanding local realities, uncovering unmet needs, and identifying opportunities for meaningful innovation.
The Nairobi Edition
For our client, the goal of the Nairobi edition was to engage with youth aged 18–35 living, working, and studying across Nairobi. This included university students, recent graduates, content creators, entrepreneurs, and young professionals navigating rapidly evolving technological landscapes.
Together with product managers, software engineers, designers, and researchers from around the world, we explored how technology and AI fit into participants’ everyday lives.
While traditional user research formed the foundation of the immersion, the centrepiece of the experience was a set of innovative Live LLM Testing methodologies designed to move beyond perceptions and directly observe how people interacted with AI systems in real-world contexts.
These methodologies—the Diary Study and Cultural Teaming—allowed participants to engage with AI in situations that reflected their actual lives, generating deeper insights into how AI succeeds, where it fails, and what it would take to build products that feel genuinely useful and locally relevant.
Building Context: Understanding the Market
1. Quantitative Baseline Study via LOOKA
We conducted a quantitative study with 300 participants in Nairobi to establish foundational behaviours, use cases, and pain points across three research tracks: AI, Information Seeking, and Content Creation and Consumption.
While these methods provided valuable context, they also surfaced an important question: What actually happens when people use AI in their daily lives? To answer that question, we turned to Live LLM Testing.

Live LLM Testing: Moving Beyond Opinions to Real Interactions
Traditional research can reveal what people think about AI. Live LLM Testing reveals how they actually use it. To explore this, we designed two complementary methodologies: a Diary Study and Cultural Teaming sessions.
1. Diary Study: Observing AI Use Over Time
To observe AI use as it unfolded over time, we designed a three-day diary study using Kitala.ai. Twenty participants were recruited and divided into two groups: 14 AI Power Users who regularly use AI to create content, accelerate work, and support learning; and 6 AI Regular Users who primarily use AI for simple tasks such as drafting messages or finding information.
The study generated 300 Human-Based Evaluations, creating a rich dataset that revealed not just whether participants liked the responses, but how those responses performed across different contexts and emotional situations.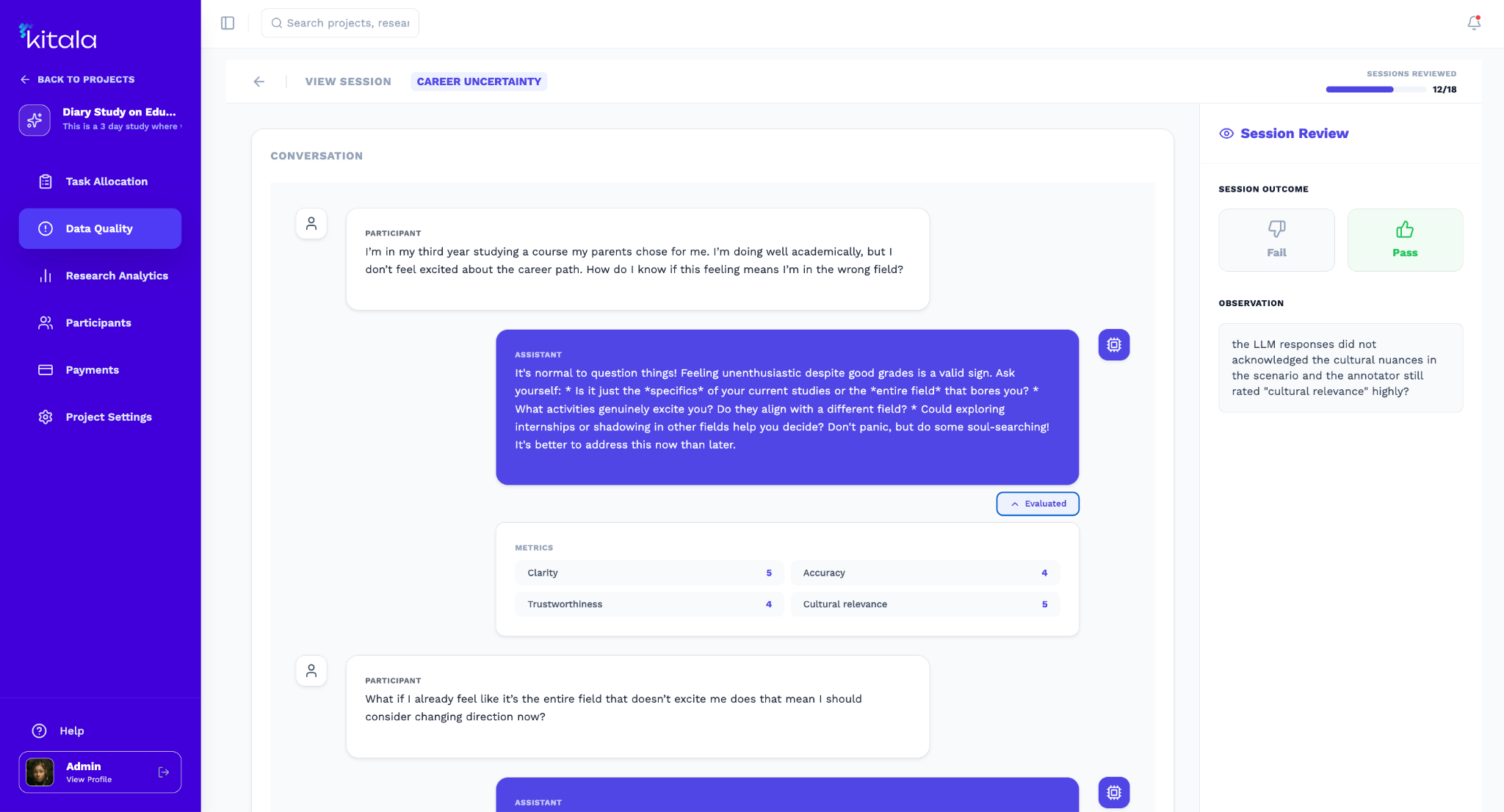
2. Cultural Teaming: Stress Testing AI in Real Life
While the Diary Study examined AI use over time, Cultural Teaming examined what happens when users actively challenge AI systems. Adapted from Chiu et al. (2024), Cultural Teaming combines scenario-based testing, structured reflection, and creative role-play to surface cultural, linguistic, and contextual dimensions that traditional evaluations often miss.
- Selected profiles: Six university students participated in in-person workshops where they interacted directly with AI chatbots, both testing how quickly AI could solve problems and intentionally attempting to push the model to its limits.
- Study Design: Participants were given realistic scenario cards covering situations such as assignment confusion, declining academic performance, career uncertainty, dropping out of university, and future planning. The sessions were designed to surface challenges that traditional evaluations often miss, including:
- Linguistic complexity: Participants used Sheng, code-switching between English and Swahili, informal abbreviations, and typographical errors.
- Emotional complexity: Participants simulated panic, fear, embarrassment, and urgency.
- Social and cultural complexity: Participants introduced strong beliefs, conspiracy-minded perspectives, questions around authenticity, and expectations rooted in local cultural norms. - Ratings and Evaluations: Following the interactions, participants evaluated responses based on cultural appropriateness, linguistic clarity, trustworthiness, and practical relevance. Together, the Diary Study and Cultural Teaming created a powerful framework for understanding not only how AI performs technically, but how it performs within the realities of everyday life.

4. Debrief & Synthesis Workshop
The immersion concluded with a half-day synthesis workshop. Researchers, designers, engineers, and product teams worked through the findings together, translating observations into concrete opportunities and product recommendations. The most significant insights emerged directly from the Diary Study and Cultural Teaming methodologies.
Core Insights and Reflections
The most significant insights emerged directly from the Diary Study and Cultural Teaming methodologies, uncovering challenges that would have remained invisible through traditional research alone.
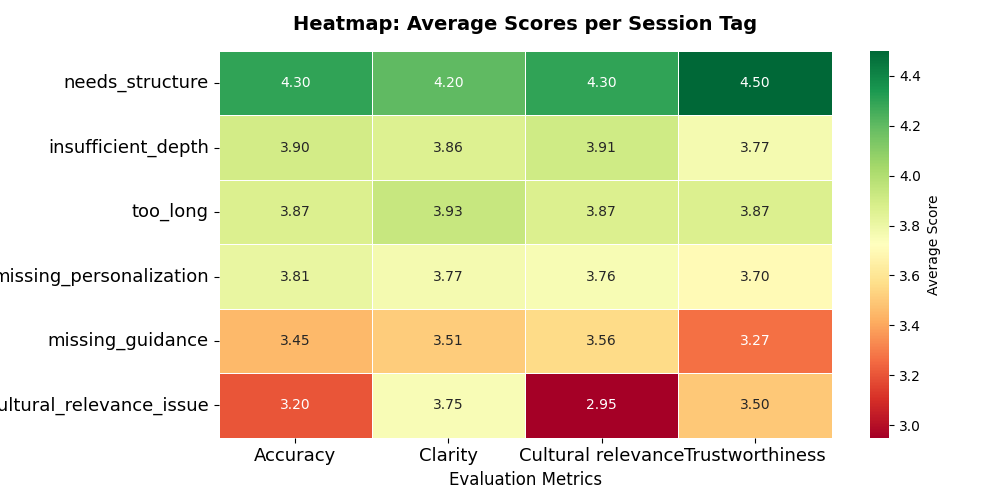
Key Insight 1: The Quiet Failure of Cultural Relevance
One of the most striking findings from the Diary Study was that cultural relevance consistently received the lowest scores across evaluations. Interestingly, participants rarely identified cultural relevance as the explicit source of dissatisfaction. Instead, they described responses as feeling foreign, slightly off, or not sounding authentic. The friction was present, but often difficult for users to articulate. This suggests that cultural relevance may be one of the most important yet least visible factors shaping trust and satisfaction with AI systems.
Key Insight 2: When AI Lacks Empathy
The Diary Study also revealed a clear pattern around emotional scenarios. When participants faced practical problems such as job applications or assignment support, AI performed relatively well. However, when emotional stakes increased, the models frequently defaulted to generic, textbook-style advice. Scenarios such as “Career Uncertainty” and “Isolation from Friends” received the lowest ratings because participants wanted more than information—they wanted responses that demonstrated understanding, empathy, and awareness of their lived realities.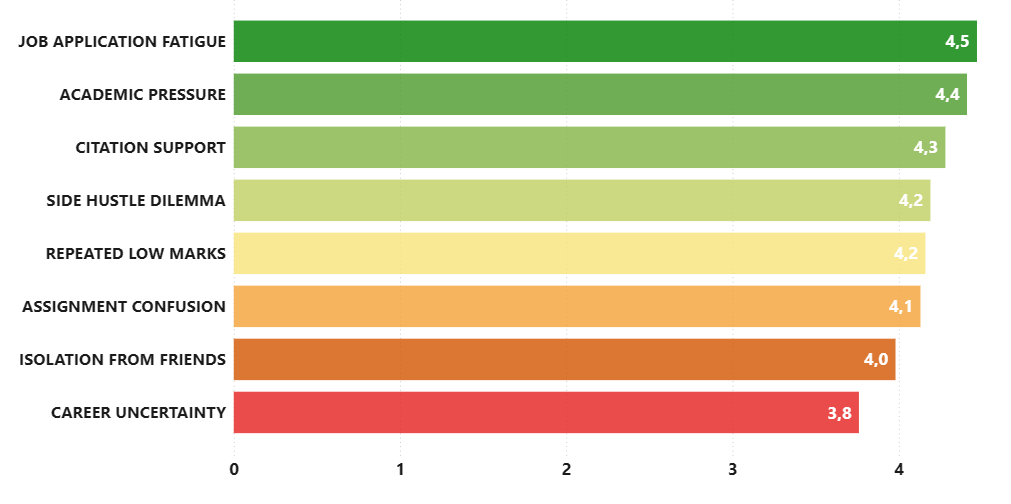
Key Insight 3: The Authenticity Gap
The Cultural Teaming workshops surfaced a related challenge. Students consistently described AI chatbots as helpful, friendly, encouraging, and flexible problem-solvers. Yet participants also pointed to a recurring gap between usefulness and authenticity. AI often struggled to capture the language patterns, social dynamics, and educational realities that shape student life in Kenya. A lack of deep local context frequently resulted in translations, explanations, and examples that felt unnatural or disconnected from participants’ experiences. This finding highlights an important distinction: building useful AI is not the same as building locally grounded AI.
As one participant noted: “The chatbot is very useful and friendly. It solves a lot of problems, although not all, because somehow the local language translation is not that authentic.”
Conclusion
The Nairobi Immersion demonstrated the value of combining deep qualitative user research with innovative Live LLM Testing methodologies. While surveys, field visits, home visits, focus groups, and ecosystem conversations provided essential context, the Diary Study and Cultural Teaming methodologies generated some of the most actionable insights. By observing how people actually interact with AI over time, and by deliberately stress-testing systems through culturally grounded scenarios, we uncovered challenges that would have remained invisible through traditional research alone. Most importantly, the immersion reinforced a critical lesson for teams building AI products across Sub-Saharan Africa: accuracy is not enough. To create meaningful impact, AI systems must also be culturally relevant, emotionally aware, linguistically authentic, and grounded in the realities of the communities they serve.
This immersion was a collaborative effort between YUX Design and a Big Tech technology and AI company in Nairobi in March 2026. Participant and client details have been anonymised.